第三方库
第三方库
第三方模块使用的基本流程
第三方模块使用的基本流程 以opencv为例
- 下载 pip install opencv-python
- 导入 import cv2
- 使用 模块名.方法名 示例 : cv2.imread('./img/cat.jpg')
对于复杂的模块来说,使用help()方法、dir()方法不能很好的满足我们的需求。如果是新手需要搭配官方文档,查阅使用实例。
这里需要注意的是:opencv模块的下载名、导入名均不是opencv。
事实上模块名、下载名与导入名也并非一种强制的规则。
建议在下载模块之前先通过搜索引擎搜索。
更多是后续的开发者出于习惯会将名称统一。例子是pandas模块。
- 下载 pip install pandas
- 导入 import pandas
- 使用 模块名.方法名 示例 : pandas.read_csv("./cat.csv")
在国内下载模块往往较慢,我们可以通过豆瓣、清华镜像站下载第三方模块。以下载scikit-learn模块为例
- python -m pip install scikit-learn==1.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
粘贴至终端,windows电脑�可以通过win+R 输入CMD
MAC可以直接搜索终端打开。
第三方模块的版本问题
第三方模块与系统模块一样,都是自定义好的一系列模块,这些模块也自然存在一些版本差异。
在使用的过程之中很可能因为版本的不匹配、方法的弃用导致示例的代码失效。
我们可以通过3个方式来解决:
1.升级至最新版本或安装指定的版本
- 安装指定的版本示例: pip install pandas==2.0.2
- 升级至最新版本示例: pip install --upgrade pandas
2.积极的查询官方文档。可在 https://pypi.org/ 上搜索对应模块,知名度较高的模块都会有系统的官方文档。
3.更换其他模块
第三方模块OpenCV
# 导入必要的包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 导入opencv
import cv2
# 使用opencv的imread方法,打开图片
img = cv2.imread('./img/cat.jpg')
# 检查类型,会发现自动转成了Numpy 数组的形式
type(img)
img
# 如果打开一张不存在的图片,不会报错,但是会返回空类型
img_wrong = cv2.imread('./img/wrong.jpg')
type(img_wrong)
img_wrong
plt.imshow(img)
# 为什么会显示的这么奇怪?
# (OpenCV和matplotlib 默认的RBG顺序不一样)
# matplotlib: R G B
# opencv: B G R
# 需要调整顺序
# 将OpenCV BGR 转换成RGB,cv2.COLOR_可以看到更多转换形式
img_fixed = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# 算法参考:RGB取均值、RGB按阈值取值、按色彩心理学公式取值R*0.299 + G*0.587 + B*0.114 = Gray
plt.imshow(img_fixed)
# 显示正常了
# 另外,我们再读取图片时也可以以灰度模式读取
img_gray = cv2.imread('./img/cat.jpg',cv2.IMREAD_GRAYSCALE)
# 显示这个灰度图
plt.imshow(img_gray,cmap="gray")
# 使用resize缩放(打开函数帮助)
img_resize = cv2.resize(img_fixed,(1000,300))
# 显示缩放后的图片
plt.imshow(img_resize)
# 翻转图片:0表示垂直翻转、1表示水平翻转,-1表示水平垂直都翻转
img_flip = cv2.flip(img_fixed,-1)
plt.imshow(img_flip)
第三方模块Scikit-learn
Scikit-learn(sklearn)、PyTorch和TensorFlow是三个在机器学习和深度学习领域广泛使用的库,各自有其优势和劣势。
如果你处理传统的机器学习问题,Scikit-learn是一个不错的选择。如果你主要进行深度学习研究或需要处理复杂的深度学习任务,PyTorch和TensorFlow是更好的选择,取决于你的偏好和需求。另外,TensorFlow在工业界有广泛的应用,因此在工业部署方面也有一定优势。
sklearn学习路线图: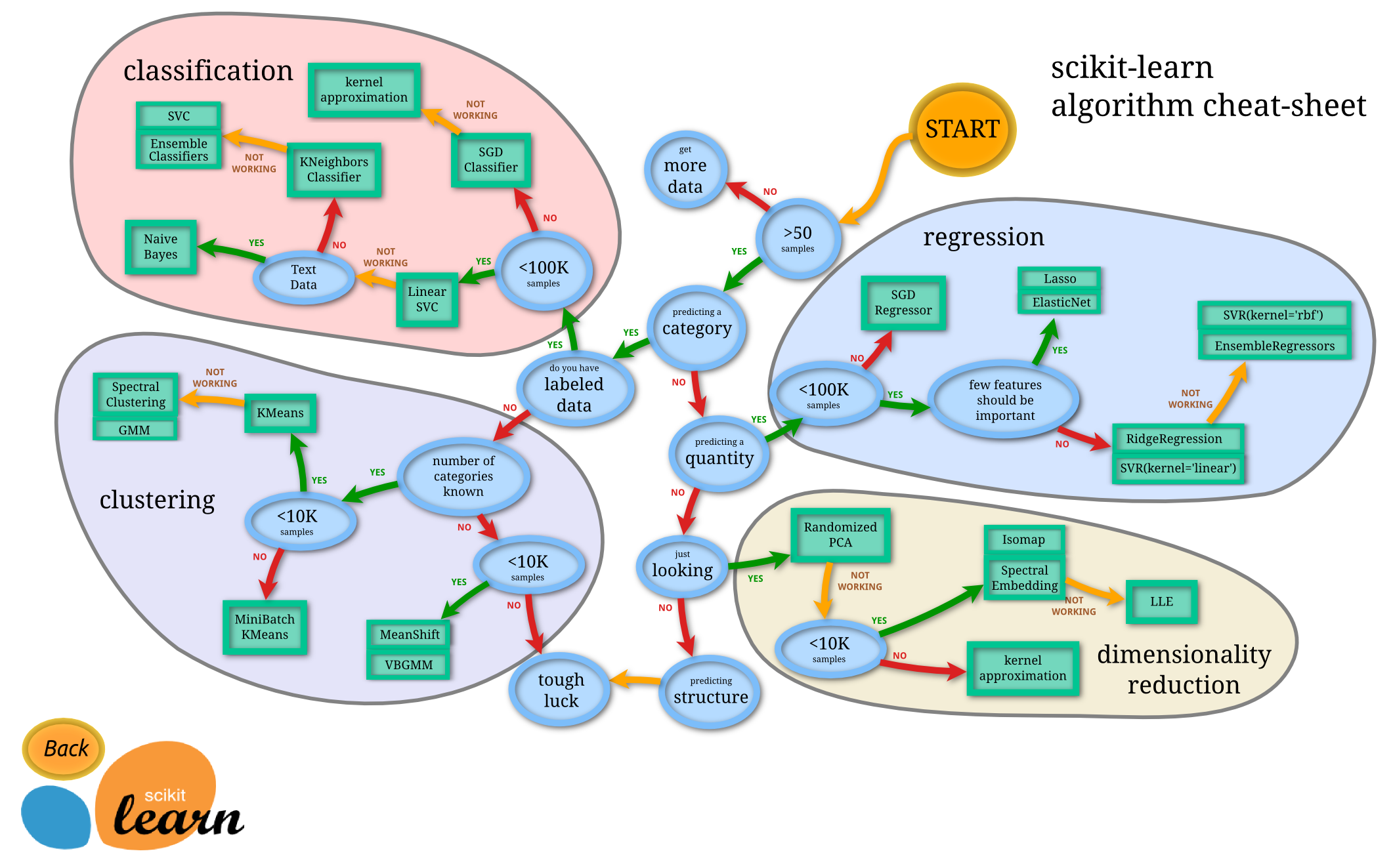
数据的来源?
参考数据集
scikit-learn 内置有一些小型标准数据集,不需要从某个外部网站下载任何文件。
scikit-learn 提供也加载较大数据集的工具,并在必要时下载这些数据集。
数据特征说明可参考 https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
这些数据集有助于快速说明在 scikit 中实现的各种算法的行为。 然而,它们数据规模往往太小,无法代表真实世界的机器学习任务。 但是作为学习使用刚刚好。
| 数据集名称 | 加载方法 | 模型类型 | 数据大小(样本数*特征数) | |
|---|---|---|---|---|
| 0 | 波士顿房价数据集 | load_boston | regression | 506*13 |
| 1 | 鸢尾花数据集 | load_iris | classification | 150*4 |
| 2 | 手写数字数据集 | load_digits | classification | 1797*64 |
| 3 | 糖尿病数据集 | load_diabetes | regression | 442*10 |
| 4 | 葡萄酒数据集 | load_wine | classification | 178*13 |
| 5 | 乳腺癌数据集 | load_breast_cancer | classification | 569*30 |
| 6 | 体能训练数据集 | load_linnerud | 多重回归 | 20*3 |
import sklearn.datasets
# 加载小数据
data = sklearn.datasets.load_wine()
data.data
from sklearn.datasets import fetch_california_housing
# 加载大数据
housing = fetch_california_housing()
housing.data
from sklearn.datasets import load_sample_image
# 加载图片
china = load_sample_image("china.jpg")
样本生成器
scikit-learn 包括各种随机样本的生成器,可以用来建立可控制的大小和复杂性人工数据集。
from sklearn.datasets import make_blobs
# 创建KNN模型数据集
'''
X为样本特征,Y为样本簇类别,共1000个样本,
每个样本4个特征,共4个簇,簇中心在[-1,-1], [0,0], [1,1], [2,2],
簇方差分别为[0.4, 0.2, 0.2]
'''
x, y = make_blobs(n_samples=1000,
n_features=2,
centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
)
from sklearn.datasets import make_regression
# 创建回归模型数据集
'''
X为样本特征,Y为样本簇类别,共1000个样本,
每个样本1个特征,
离散度为2
'''
x2,y2 = make_regression(n_samples=1000, n_features=1, n_targets=1, noise=2)
自有数据集
我们手上可能刚好有一些数据集,可以通过pandas或者numpy读取
# 通过pandas或者numpy读取
import pandas as pd
import numpy as np
data = pd.read_csv('./data/iris.csv')
# 通过numpy读取
data = np.loadtxt('./data/iris.csv', delimiter=",", skiprows=1)